Docker Build Cloud
Docker Builds: Now Lightning Fast
Announcing Docker Build Cloud general availability
What is Docker?
Accelerate how you build, share, and run applications
Docker helps developers build, share, run, and verify applications anywhere — without tedious environment configuration or management.
Build
Spin up new environments quickly
Develop your own unique applications with Docker images and create multiple containers using Docker Compose.
Integrate with your existing tools
Docker works with all development tools such as VS Code, CircleCI, and GitHub.
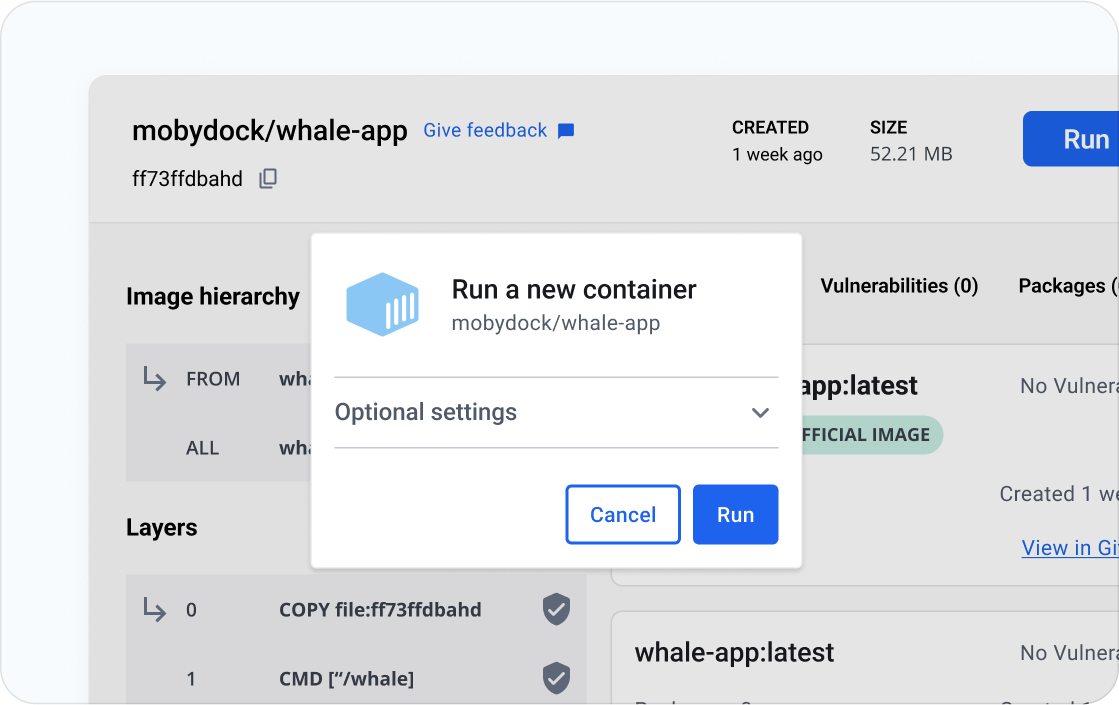
Containerize applications for consistency
Run in any environment consistently from on-premises Kubernetes to AWS ECS, Azure ACI, Google GKE, and more.

Share
Build with verified, trusted content
Visit Docker Hub to browse Docker Trusted Content from our verified publishers or Docker Official Images.
Collaborate with your team
Pull and publish images from Hub for easy sharing between team members, organizations, or the broader community.
Secure your workspaces
Ensure best practices with image access management, registry access management, and private repositories.

Why use Docker?
Trusted by developers.
Chosen by Fortune 100 companies.
Docker provides a suite of development tools, services, trusted content, and automations, used individually or together, to accelerate the delivery of secure applications.

20M+
monthly developers
7M+
applications
20B+
monthly image pulls
Container development
New to containers?
We got you covered! Get started with the basics with our guide to containers, including what they are, their advantage over virtual machines, and more.


Connect
Meet the community
Stop by any of the hundreds of meetups around the world for in-person banter or join our Slack and Discourse for virtual peer support. Our Docker Captains are also a great source of developer insight and expertise.
Join our open source program
Our Docker-Sponsored Open Source program is ideal for developers working on non-commercial projects.
Develop from code to cloud with partners that you trust
Our partnerships ensure that your development pipeline network will work in your preferred environment — whether local or in the cloud.
![]() Simplify the development of your multi-container applications from Docker CLI to Amazon EKS and Serverless.
Simplify the development of your multi-container applications from Docker CLI to Amazon EKS and Serverless.
Integrate with your favorite tools and images
How to get started
Your path to accelerated application development starts here.
Download Docker
Learn how to install Docker for Mac, Windows, or Linux and explore our developer tools.
Containerize your first app
Develop a solid understanding of the Docker basics with our step-by-step developer guide.
Publish your image on Docker Hub
Share your application with the world (or other developers on your team).
Choose a subscription that’s right for you
Find your perfect balance of collaboration, security, and support with a Docker subscription.